중국 AI 스타트업 딥시크(DeepSeek)에서 만든 추론모델 딥시크 R1의 등장으로 AI 업계 파문이 일고 있다. 경량화된 파라미터를 기반으로 저렴한 비용 대비 뛰어난 성능으로 AI 발전방향의 패러다임을 제시했다는 점에서 대표격으로 주목 받고 있다.
딥시크 R1은 강화 학습을 통해 스스로 추론 능력을 발전시키는 방식을 채택해 AI 모델 개발 비용과 리소스를 크게 낮췄으며, 이를 통해 적은 파라미터만으로도 높은 정확도와 성능 지표를 보여줘 ‘효율성’면에서 AI 상용화를 한 단계 진일보시켰다고 평가받는다.
AWS·엔비디아, R1 모델 배포 가속
가성비 추론 모델 온디바이스 AI 이점
딥시크, 사전학습 구축 비용 26억달러↑
중국 AI 스타트업 딥시크(DeepSeek)에서 만든 추론모델 딥시크 R1의 등장으로 AI 업계 파문이 일고 있다. 경량화된 파라미터를 기반으로 저렴한 비용 대비 뛰어난 성능으로 AI 발전방향의 패러다임을 제시했다는 점에서 대표격으로 주목 받고 있다.
딥시크 R1은 강화 학습을 통해 스스로 추론 능력을 발전시키는 방식을 채택해 AI 모델 개발 비용과 리소스를 크게 낮췄으며, 이를 통해 적은 파라미터만으로도 높은 정확도와 성능 지표를 보여줘 ‘효율성’면에서 AI 상용화를 한 단계 진일보시켰다고 평가받는다.
■ AWS·엔비디아, R1 모델 배포 가속...온디바이스 추론 혁신 기대
지난 20일 딥시크 R1을 비롯해 딥시크 R1-제로와 R1-디스틸 모델이 함께 공개됐으며, 오픈소스 기반의 R1 모델은 빠르게 전세계 개발자들을 통해 검증되며 다양한 테스트 결과를 내놓았고, 이후 배포·활용 서비스로 이어졌다.
AWS는 아마존 베드록과 아마존 세이지메이커AI를 통해 딥시크 R1 모델을 제공한다고 발표했으며, 세레브라스는 DeepSeek R1-Distill-Llama-70B을 미국 서버에서 호스팅한다고 지난 29일 발표한바 있다.
또한 엔비디아는 딥시크 R1을 엔비디아 추론 마이크로서비스 ‘NIM’에서 프리뷰로 제공한다고 밝혔으며, “단일 엔비디아 HGX H200 시스템에서 최대 초당 3,872개의 토큰을 처리할 수 있다”고 설명했다. API 지원도 곧 제공될 예정인 것으로 전해진다.
딥시크에서 공개한 테크니컬 리포트 기반으로 7B LLM TinyZero를 구현한 버클리 박사과정의 Jiayi Pan은 트위터를 통해 30달러 비용으로 굉장히 작은 모델에서도 ‘아하 모먼트(Aha Moment)’를 구현할 수 있는 것을 증명했다. ‘아하 모먼트’는 AI 모델이 스스로 문제를 해결하면서 시행착오를 통해 성능이 향상되고 쉬운 문제에서 복잡한 문제로의 해결까지 가능하게 되는 발전을 보여준다.
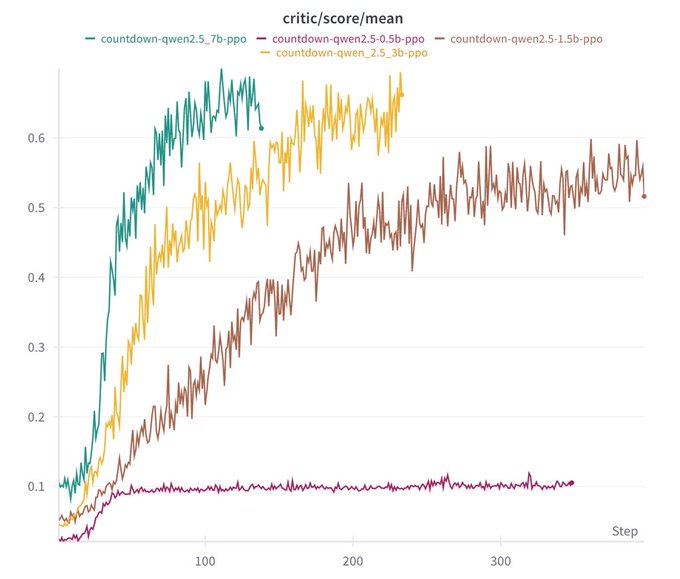
▲딥시크 R1 제로 Qwen 2.5 기반 파라미터별 스코어 그래프(출처-Jiayi Pan X)
Jiayi Pan은 딥시크 R1 제로 Qwen 2.5 기반 0.5억 파라미터부터 7억파라미터까지 테스트한 결과를 보면, 0.5억 파라미터 모델을 제외하고 모두 스코어가 상승하는 결과를 나타냈다. 7억파라미터 수준의 모델은 굉장히 소형화된 AI 모델로 온디바이스 AI 애플리케이션에 적용할 만큼 모델 크기가 작다고 할 수 있다.
일각에서는 스마트폰의 추론 성능 향상 및 무선 이어폰의 노이즈 캔슬링 성능 강화, AI 스피커의 음성인식율 향상 등 다양한 온디바이스 AI 기기에서 딥시크 R1 제로와 같은 강화 학습 기반의 소형화된 추론 AI 모델이 도입될 가능성이 열린 것으로 평가하고 있다.
딥시크 R1과 오픈AI o1-mini와 비교에서 100만 토큰당 입력비용은 딥시크 0.14~0.55달러, 오픈AI 1.5~3달러이며 출력비용도 2.19달러 대 12달러로 큰 격차를 보이며 딥시크가 저렴한 것으로 나타났다. 이에 오픈 AI는 지난 31일 o3-mini를 공식 출시하며 기존 모델 대비 비용 효율과 성능을 개선했다. 100만 토큰당 입력 비용은 0.55달러로 딥시크 R1과 동급으로 맞췄으며, 출력비용은 4.4달러로 책정해 2배 수준까지 좁혔다.
■ 딥시크, 사전학습 구축 비용 26억달러↑
기존에 알려진 딥시크 개발 비용인 557만6,000달러 한화로 80억원 가량의 비용을 두고 국내외 언론사들이 설왕설래하는 가운데 전문가들은 이러한 비용이 딥시크 V3에서 공식적인 학습비용만을 계산한 것이라며, 이전의 연구비 및 실험비 등을 포함하지 않음을 밝히고 있다고 강조한다.
반도체 및 AI 산업 연구기관 SemiAnalysis가 지난 31일 보도한 내용에 따르면 딥시크는 H800 약 1만대와 H100 약 1만대에 접근할 수 있으며, 분석에 따르면 딥시크의 총 서버 용량은 약 16억달러로 운영 비용에만 10억달러 가까이 이를 것으로 추정했다.
SemiAnalysis는 ‘하드웨어 지출은 5억 달러보다 훨씬 높을 것이라고 확신한다’고 강조하며 논문의 600만달러 비용은 사전 학습에서의 GPU 비용만을 나타낸 것이라고 분석했다.
다만 전문가들은 AI 모델 개선 방향에서 추론 비용이 줄어들고, 더 작은 모델로 더 높은 성능을 발휘하는 것이 추세적인 대세라고 입을 모은다. SemiAnalysis는 ‘알고리즘 개선과 최적화로 비용이 10배 감소하고 기능이 증가하는 것을 볼 수 있다’면서, 딥시크가 지금 수준보다 연말까지 비용을 5배 더 하락시키는 결과물을 내더라도 놀라지 말 것을 주문했다.
이는 AI 추론 모델에서 알고리즘적으로 최적화해 성능·정확도는 유지하면서 비용은 저렴한 모델들이 앞으로 더 많이 나올 것을 시사했다. 최근 출시된 구글의 Gemini Flash 2.0 Thinking을 비롯해 오픈 AI의 o3-mini 등 다양한 소형 모델들이 경쟁적으로 가성비를 향상시키며 AI 산업 발전을 추동하고 있다.
모델 경쟁이 치열해지고 비용은 더 저렴해질수록 온디바이스 AI 시장의 개화와 소비자 체감도증가 또한 본격적인 속도를 낼 것으로 기대된다.








